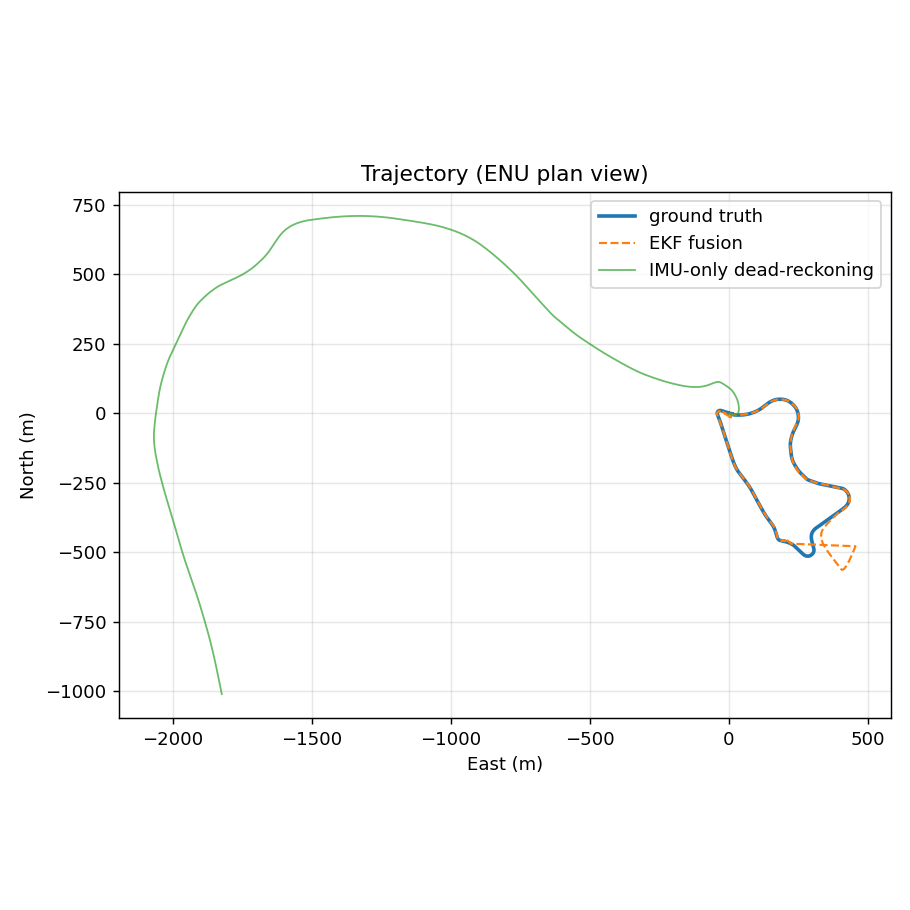
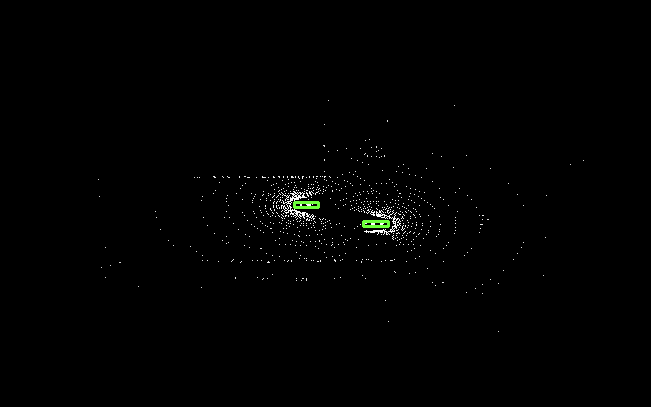
point cloud · sample_office_scene.ply · 120k pts
This is a subsampled preview (120k of ~2M points). Watch the
full reconstruction video ↗,
or browse the full playlist ↗.
$ whoami
Hi, I'm Diwakar Ravichandran
Robotics Perception & GPU Inference Engineer
M.S. in Robotics from UC Riverside, working at the intersection of SLAM, 3D reconstruction, and GPU systems. I take research ideas all the way to shipped, production code — from drone-based 3D reconstruction to custom CUDA kernels for real-time perception and LLM inference.
 ● tracking · pose locked
● tracking · pose locked