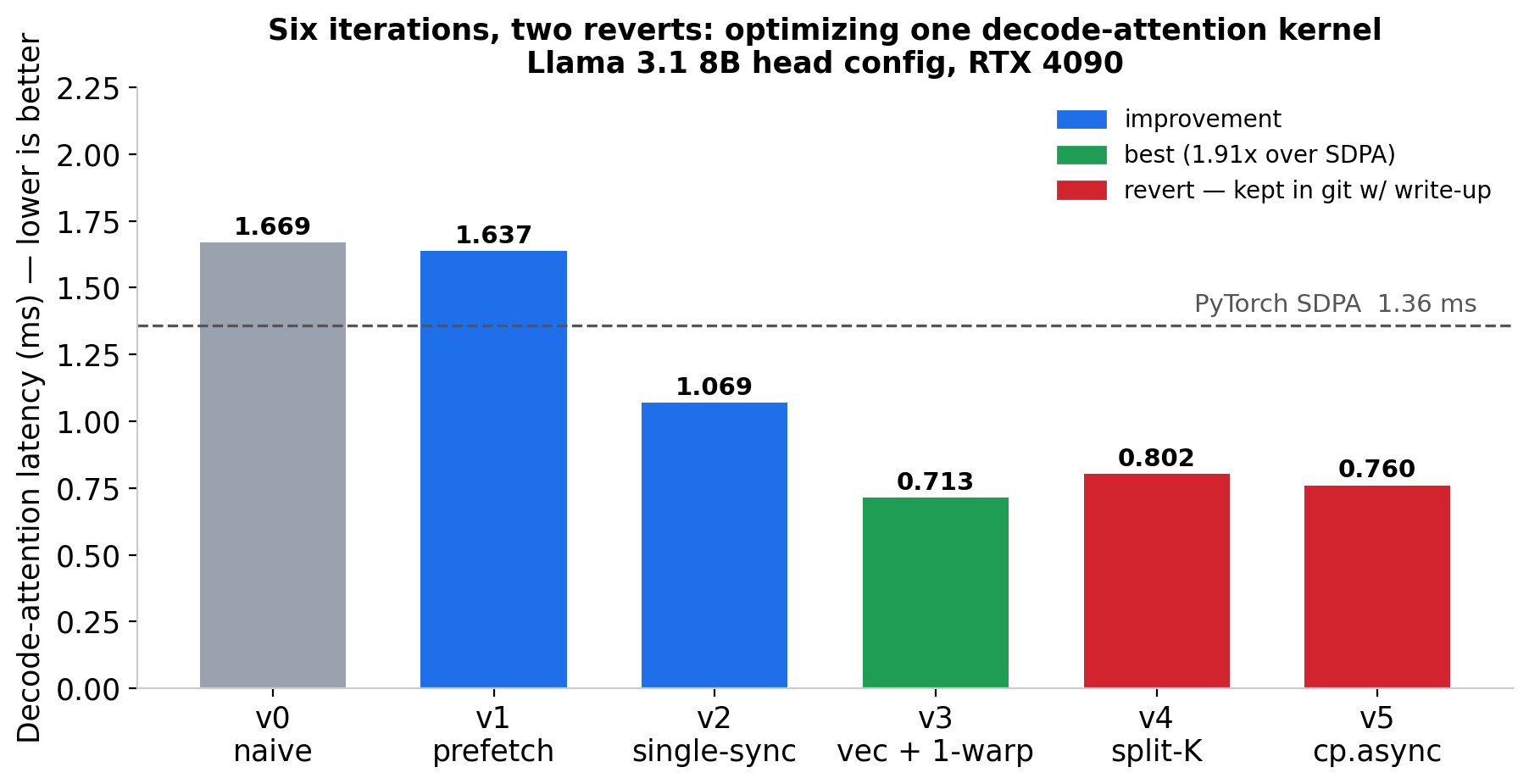
It took six iterations to get an LLM decode-attention kernel 1.91× faster than PyTorch's SDPA (FlashAttention/cuDNN). Two of those six steps were reverts. The reverts taught me more than the wins.
The third category
Every GPU optimization tutorial teaches two ways a kernel can be slow: memory-bandwidth-bound or compute-bound. Most of mine were neither. They were dependency-chain-bound — gated by the length of the per-iteration critical path, not by any hardware resource. That third category flips your intuition, and it cost me real time until it sank in.
Three results that went against intuition
- I traded full GPU occupancy for single-warp blocks — dropped to ~33% occupancy — and got 1.5× faster. The "wasted" warps were just idling at sync barriers, not hiding any latency.
- I shrank the KV cache 2× with INT8. Latency didn't move at all. Fewer bytes only helps if bytes are the bottleneck. (INT4 later did win — because it also shortened the chain, not just the byte count.)
- I split the work across 5× more SMs to "fill the GPU." It got slower. More parallelism does nothing when the per-iteration chain is the ceiling.
The discipline that fixed it
Predict the direction AND the magnitude of every change before you run it. If your prediction is off by 4×, you don't understand the bottleneck yet — and the measurement won't explain it, it'll just tempt you to guess again.
Both reverts are still in git, each with its diagnostic write-up. The write-up outlived the code: the next kernel with the same shape, I'd already paid for the diagnosis.
The checklist I now run before touching any kernel
- Bandwidth-, compute-, or chain-bound? (Most are chain-bound.)
- What lever shortens that specifically?
- What magnitude do I predict — and does the measurement match?
If you want the first-principles version — what attention actually computes, the GPU mental model, and decode attention built up naive → fast — that's the Foundations field guide. Code and per-phase write-ups are on GitHub.